
I - À propos
Les RegEx (fusion de "Regular" et "Expression") sont des expressions régulières très précieuses et utilisables dans de nombreux langages informatiques (PHP, Bash, Shell, Htaccess...). Elles sont composées de chaînes de caractères contenant des caractères spéciaux et des caractères standards et permettent de raccourcir en une ligne, une commande très longue grâce au modèle que l'on construit avec elles, que l'on appelle « motif ».
Les regex sont aussi appelées parfois "Expressions Rationnelles" car effectivement elles permettent rationnellement de définir, selon une certaine syntaxe, un ensemble de chaînes de caractères possibles et donc de pouvoir rechercher des occurrences précises pour ainsi pouvoir les manipuler comme on le souhaite.
Si vous codez ou programmez, vous avez sans doute déjà rencontré des regex. Cette page est un aide mémoire pour mieux les appréhender et vous permettre de comprendre un bout de script trouvé sur le net par exemple ou aussi de vous faciliter la tâche si vous avez besoin de faire certains traitement en PHP ou d'autres langages.
II - Construction d'une regex
Une regex se construit à l'aide de caractères spéciaux, en voici la liste :
Avertissement : Notez bien que les guillemets ne doivent surtout pas être utilisés en ouverture et fermeture dans un fichier .htaccess de serveur Apache, au risque sinon de provoquer le fameux « HTTP Error 500 (Internal Server) ».
Délimiteurs
Les symboles ^ et $ indiquent le début ou la fin d'une chaîne, et permettent donc de la délimiter.
Voici quelques exemples :
- ^logiciel chaîne qui commence par « logiciel »
- libre$ chaîne qui se termine par « libre »
- ^être$ exactement le mot « être » (commence ET fini)
- ^(être).*(être)$ Une chaîne qui commence et se termine par « être » - Par exemple : « être ou ne pas être » ou aussi « être sans avoir été n'est pas être ».
Notions de nombre
- Le symbole * signifie « zero ou plusieurs »
- Le symbole + signifie « un ou plusieurs »
- Le symbole ? signifie « un ou aucun »
Voici quatre exemples :
- abc* chaîne qui contient « ab » suivie de zero ou plusieurs « c » (ab, abc, abccc ...)
- abc+ chaîne qui contient « ab » suivie de un ou plusieurs « c » (abc, abcc, abccc ...)
- abc? chaîne qui contient « ab » suivie de zero ou un « c » (ab ou abc)
- ^abc+ chaîne commençant par « ab » suivie de un ou plusieurs « c » (abc, abcc, abccc ...)
Exclusion
Le point d'exclamation, signifie « Tout ce qui n'est pas » ou « Tout ce qui ne correspond pas », ainsi :
- !^www chaîne ne commençant pas par « www »
- !^abc+ chaîne ne commençant pas par « ab » suivie de un ou plusieurs « c ». Seront donc exclus abc, abcc, abccc, abcccc etc.
Limites de nombre
Les accolades {X,Y} permettent de donner des limites chiffrées.
- abc{2} chaîne qui contient « ab » suivie de deux « c » (abcc uniquement).
- abc{2,} chaîne qui contient « ab » suivie de deux « c » ou plus (abcc, abccc, abcccc..). Notez que le premier nombre de la limite {2} est obligatoire, mais pas le dernier "{,}".
- abc{2,4} intervalle - chaîne qui contient « ab » suivie 2, 3 ou 4 « c », (donc abcc, abccc et abcccc).
Les symboles * + ? vus ci-dessus sont équivalents à {0,}, {1,} et {0,1}. Néanmoins utilisez de préférences - + et ? car ils sont plus courts et plus vite compréhensibles.
Séquences de caractères
Les parenthèses ( ) représentent une séquence de caractères.
a(bc)* chaîne qui contient « a » suivie de zéro « bc » ou plus (de « bc »).
le (bla)* chaîne qui contient « le » suivie de zéro « bla » ou plus ("le "; "le bla", "le blabla", "le blablabla", etc.).
Alternative
La barre verticale | (pipe en anglais) se comporte en tant qu'opérateur « OU ».
- un|le chaîne qui contient « un » ou « le » (exemples : un, une, unie... le, les, lettre, leur...).
- (la|le) libertaire chaîne qui contient « la libertaire » ou « le libertaire ».
- (a|b)* chaîne qui contient une suite de « a » ou de « b » (exemples : a, b, ab, ba, aa, bb, abb, aab, bba, bbbba, aaaabbb...).
Tout (une fois)
Le point . signifie « n'importe quel caractère (une fois) », aussi bien une lettre, un chiffre, une espace, qu'un caractère spécial, un tiret ou un underscore.
Hormis le retour à la ligne et le saut de ligne, car ils ne sont pas des caractères à proprement parler.
^.{2}$ chaîne qui contient deux caractères seulement, exprimés par 2 fois "le point" (exemples : le, la, a4, 72, v*, !!, "", '', aa, bb, ab, ba, az...).
Classe de caractères, autorisés ou interdits
- Les crochets [ ] définissent une classe de caractères (ou liste de caractères) autorisés ou interdits.
- Le tiret "-" entre crochet permet de définir un intervalle (sauf s'il est placé au début ou à fin, dans ce cas il signifiera son propre caractère : le tiret).
- Le caractère ^ (accent circonflexe) après le premier crochet spécifie l'interdiction.
- [abc] chaîne qui contient un « a », un « b », ou un « c ». Équivalent à (a|b|c) - Notez ici les parenthèses et non les crochets.
- [a-z] chaîne qui contient un caractère compris entre « a » et « z », donc tout l'alphabet (ici en minuscule).
- ^[a-zA-Z] chaîne qui commence obligatoirement par une lettre (minuscule ou majuscule). Ici l'accent circonflexe avant les crochets comme à son habitude spécifie un début.
- ^[^a-zA-Z] chaîne qui ne commence ni par une lettre minuscule ni par une majuscule (l'accent circonflexe entre les crochet spécifiant bien l'interdiction).
L'échappement pour rechercher des caractères spéciaux :
Pour rechercher un caractère faisant partie des 16 caractères spéciaux il faut "l'échapper", c'est à dire le faire précéder d'un \ antislash (dit aussi barre oblique inversée ou encore backslash). Les 16 symboles devant être échappés sont ^ $ \ | { } [ ] ( ) ? # ! + * . Précédé d'un antislash, ils seront ainsi recherchés tels qu'ils sont et non selon leur fonction particulière dans des regex. Exemple : si vous devez rechercher un antislash \ il faudra le doubler ainsi \\
Une exception néanmoins, il ne sera pas nécessaire de les échapper lorsqu'ils se trouvent entre des crochets [ ].
En effet dans les crochets, chaque caractère représente ce qu'il est vraiment.
Cas particuliers entre des crochets :
• Pour représenter un crochet de fermeture ] et ne pas avoir à l'échapper, il faut le mettre en premier, ou après un accent circonflexe "^" si c'est une interdiction.
• Un tiret "-" se met en dernier (sinon vous devrez l'échapper).
• Si vous voulez faire du caractère "^" un élément de la liste, placez-le n'importe où, sauf en premier.
- [\\+?{}.] Ceci défini une chaîne qui contient un de ces 6 caractères (notez le double \ pour échapper le symbole \).
- []-] Ceci défini une chaîne qui contient le caractère « ] » ou le caractère « - »
- [^.] correspond à tout ce qui n'est pas un point
III - Récapitulatif des caractères spéciaux utilisés comme opérateurs dans les regex
| Caractères | Usages |
|---|---|
| [] | Les crochets définissent une liste de caractères autorisés. |
| () | Les parenthèses définissent un élément composé de l'expression régulière qu'elle contient. |
| {} | Les accolades lorsqu'elles contiennent un ou plusieurs chiffres séparés par des virgules représentent le nombre de fois que l'élément précédant les accolades peut se reproduire. Par exemple p{3,5} correspond à ppp, pppp ou ppppp. |
| - | Un tiret entre deux caractères dans une liste représente un intervalle (par exemple [a-d] représente [abcd]). |
| . | Le caractère "point" représente un caractère unique. |
| + | Le caractère "plus" indique la présence d'un ou plus d'élément le précédant. |
| * | Le caractère "astérisque" indique la présence d'aucun ou de plusieurs éléments le précédant. |
| ? | Le caractère "point d'interrogation" indique la présence éventuelle de l'élément le précédant. |
| | | Le caractère "|" (pipe) représente l'occurrence de l'élément situé à gauche ou celui situé à droite de cet opérateur. Par exemple Tout blanc|Tout noir validera "Tout blanc" ou "Tout noir", mais pas "blanc","noir", "tout blanc", "tout noir" (sans majuscule à "tout"). |
| ^ | Le caractère "^" placé en début d'expression signifie « chaîne commençant par » Alors que placé à l'intérieur d'une liste (entre crochets) "^" signifie « ne contenant pas les caractères suivants ». |
| $ | Le caractère "$" placé en fin d'expression signifie « chaîne finissant par ... ». |
IV - Les classes de caractères
Pour vérifier si une chaîne contient des caractères d'un certain type (numérique, alphanumérique, ...) sans avoir à les énumérer, nous pouvons aussi utiliser les « classes de caractères» dont la syntaxe est [:classe:]. Ces classes de caractères sont celles définies par UNIX.
Notez que les crochets dans ces noms de classe font partie des noms symboliques et doivent donc être, en plus, inclus dans d'autres crochets.
Par exemple, pour rechercher des caractère d'espacement, il vous faudra faire [[:space:]]
Voici un tableau récapitulant certaines de ces classes :
| Nom de la classe | Description |
|---|---|
| [:alnum:] | Caractères alphanumériques, équivalent à [A-Za-z0-9] |
| [:alpha:] | Caractères alphabétiques [A-Za-z] |
| [:blank:] | Caractères blanc (espace, tabulation) |
| [:cntrl:] | Caractères de contrôle ou caractères non-imprimables utilisés pour la mise en page. Exemple : /t, /n, /r (ce sont les premiers du code ASCII). |
| [:digit:] | Chiffre [0-9] |
| [:graph:] | Caractères d'imprimerie (tout caractère imprimable, à l'exception de ceux faisant partie de la classe de caractères espace) |
| [:lower:] | Lettres minuscules, équivalent à [a-z] |
| [:print:] | N'importe quel caractère imprimable |
| [:punct:] | Caractères de ponctuation ! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~. |
| [:space:] | Caractère d'espacement (tabulation, nouvelle ligne, tabulation verticale, saut de page, retour chariot et l'espace) |
| [:upper:] | Lettres majuscule, équivalent à [A-Z] |
| [:xdigit:] | Caractères hexadécimal, équivalent à [0-9A-Fa-f] soit 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f. |
V - Raccourcis pour les classes de caractères souvent employés
En effet pour gagner du temps, il est souvent plus simple et plus lisible d'utiliser les raccourcis ci-dessous.
Par exemple, au lieu de se servir de [a-zA-Z0-9_] pour rechercher tout caractère « verbal » (ce qui signifie généralement « alphanumérique » : lettres, chiffres, quelle que soit la casse avec l'underscore "_" en prime), le raccourcis \w couvre tout cela.
| Raccourcis | Explications |
|---|---|
| \d | Représente un chiffre. Équivalent de [0-9]. |
| \w | Représente un caractère de mot (mot dans le contexte expression régulière, non pas dans le contexte de la langue française). Équivalent de [a-zA-Z0-9_]. |
| \s | Représente un caractère d'espacement. Équivalent (en PHP et Python) de [\r\n\t\f\v ] |
| \D | Représente un caractère qui n'est pas un chiffre (le contraire de \d). |
| \W | Représente un caractère qui n'est pas un caractère de mot (le contraire de \w). |
| \S | Représente un caractère qui ne soit pas d'espacement (le contraire de \s). |
VI - Pré-analyses
Positive et Negative Lookahead & Positive et Negative Lookbehind
Les pré-analyses des regex permettent de faire correspondre un motif uniquement s'il est suivi ou s'il est précédé d'un autre motif.
Mais leur particularité c'est aussi, qu'après la parenthèse fermante de ces pré-analyses, le moteur de la regex se retrouvera à l'endroit même de la chaîne où il a commencé à chercher.
En d'autres termes, il n'aura pas bougé. Ce qui est très pratique, car à partir de cette position, le moteur de recherche, pourra recommencer à faire correspondre des caractères, ou encore, chercher quelque chose d'autre (avec pourquoi pas une nouvelles pré-analyse).
Ci-dessous, la validation d'un mot de passe en est un bon exemple. Car si vous testez celle-ci, vous noterez que les chiffres, les minuscules, les majuscules ou les caractères spéciaux pourront être placés n'importe où dans le mot de passe, même si pourtant les groupes entre parenthèses sont dans un ordre différent.
Il existe 4 pré-analyses, 2 positives et 2 négatives (marquée par le point d'exclamation !)
- (?= … )
- (?<= … )
- (?! … )
- (?<! … )
Exemples de pré-analyses :
- (?= agate) Lookahead - Affirme que ce qui suit immédiatement la position actuelle dans la chaîne est « agate »
- (?<= olivier) Lookbehind - Affirme que ce qui précède immédiatement la position actuelle dans la chaîne est « olivier »
- (?! julie) Negative Lookahead - Affirme que ce qui suit immédiatement la position actuelle dans la chaîne de caractères n'est pas « julie »
- (?<! daniel) Negative Lookbehind Affirme que ce qui précède immédiatement la position actuelle dans la chaîne n'est pas « daniel »
VII - Exemples de regex
- hirondelle chaîne contenant « hirondelle ». Par exemple dans "une hirondelle" ou "hirondelles", seule "hirondelle" sera prise en compte (ni "une", ni le "s" du pluriel).
- ^[[:alnum:]]+$ Chaîne composée d'un ou plusieurs caractère(s) alphanumérique(s).
- [[:punct:]]|[[:space:]] Chaîne contenant un caractère de ponctuation ou un caractère d'espacement.
- ^[[:digit:]]+$ Chaîne contenant un chiffre ou nombre.
- . Recherche toutes les lignes contenant au moins un caractère (rappel : un "espace" est considéré comme un caractère).
- .. Recherche toutes les lignes contenant au moins deux caractères.
- ^# Recherche toutes les lignes commençant par un "#"
- ^$ Recherche toutes les lignes vides (commençant et finissant par rien, synonyme de chaînes vides).
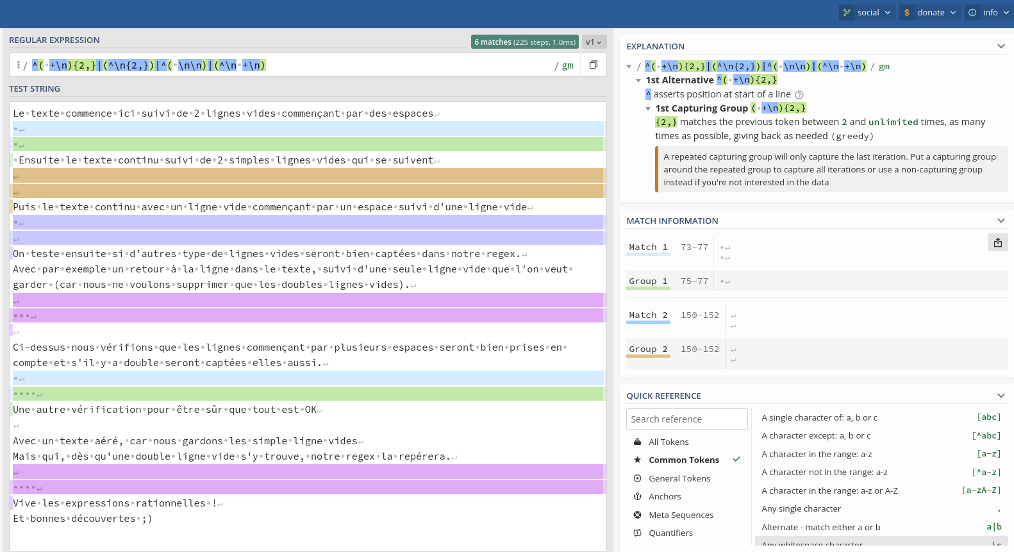
- ^\n{2,} Recherche chaque fois qu'il existe deux ligne vides (sur Linux).
-
^( +\n){2,}|(^\n{2,})|^( \n\n)|(^\n +\n)
Recherche :
- Les doubles lignes vides commençant par des espaces
- OU deux lignes vides qui se suivent
- OU une ligne vide commençant par un espace suivie d'une ligne vide
- OU une ligne vide suivi d'une ligne vide commençant par un ou plusieurs espace(s).
- OU une ligne vide suivi d'une ligne vide commençant par un ou plusieurs espace(s).
Cette regex est très pratique pour supprimer toutes les lignes vides en double. Voir un aperçu du test de cette Regex.
Ou testez là en direct ici : https://regex101.com/r/WqGyTm/1
- }$ Recherche toutes les lignes finissant par un "}"
- } *$ Recherche toutes les lignes finissant par un "}" suivi ou non d'espaces.
- [abc] Recherche toutes les lignes contenant un des caractères "a", "b" ou "c".
- ^[abc] Recherche toutes les lignes commençant soit par un "a", soit un "b", soit un "c".
- ^.+$ Recherche toutes les lignes ayant 1 caractère (n'importe lequel) ou plus.
- [Pp]lantes? Recherche les mots : Plante, Plantes, plante et plantes.
-
Une regex pour la validation d'un mot de passe
Demander qu'un mot de passe comporte au moins : un chiffre, une lettre minuscule, une lettre majuscule, un caractère spécial.
en ayant minimum 8 caractères et 16 maximum :^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[!?*\-+_#%]).{8,16}$
Notez ici l'anti-slash "\" avant le tiret "-" pour autoriser le "-" dans cette regex en tant que tel.
Car le tiret "-" est un symbole particulier au même titre que le crochet de fermeture "]" et l'accent circonflexe "^".
Suivant où ils sont placés, ils rempliront où non des fonctions particulières.
NB. Pour ne pas avoir à échapper ce "-" (tiret) nous aurions pu le placer à la fin du motif entre crochet (voir exceptions particulière plus haut). -
En PHP, cette validation de mot de passe pourrait donc être codée ainsi :
<?php
// La variable du mot de passe est : $PassValid
// On s'assure qu'il est bien valide
if(preg_match('@^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[!?*\-+_#%]).{8,16}$@', $PassValid))
{ echo '<p>Mot de passe validé !</p>'; }
else { echo '<p>Votre mot de passe ne remplit pas les exigences demandées.</p>'; }
?>Notez ci-dessus que les délimiteurs de la fonction PHP "preg_match" sont des arobases, pour pouvoir rechercher le dièse "#" sans avoir besoin de l'échapper.
En règle général on choisi un délimiteur dont on n'a pas besoin dans sa regex.
Ceux-ci peuvent être l'un de ces 22 caractères "/ @ # % & ' , : ; = _ ` ~ - $ . ^ ! ? * + |
Je vous déconseille néanmoins les huit derniers, car ils sont fréquemment utilisés comme opérateur dans un motif, cela vous évitera de devoir les échapper (et perdre du temps à comprendre pourquoi votre regex ne fonctionne pas comme attendue).Et en PHP, pour utiliser une regex avec certaines fonctions, telles que "preg_match" ou "preg_replace" il faut bien sûr l'entourer pas des délimiteurs mais aussi par des apostrophes (ou des guillemets), comme ci-dessus.
-
Exemple de regex en bash (dans un terminal), la commande :
grep -E '[Pp]lantes?' jardin.txtRetournera toutes les lignes du fichier jardin.txt ou les mots : Plante Plantes plante plantes seront présents, y compris celles avec des fautes de frappe telles que "maplante" ou "plantee" etc. L'option de grep -E est nécessaire pour indiquer que l'on va se servir des Expressions rationnelles.
-
Une regex pour vérifier qu'un numéro de téléphone français est bon :
Ce numéro pourra commencer par 01, 02... mais aussi par +331, + 332... et devra comporter des séries de 2 chiffres avec ou sans 1 point (ou 1 espace), quatre fois.
^(0|\+33)[1-9]((\.?| ?)[0-9]{2}){4}$
Ainsi par exemple : 01 42 68 53 00, 0142685300, 01.42.68.53.00, +331 42 68 53 00, +33142685300 et +331.42.68.53.00 seront acceptés par cette vérification.
- Exemple d'une regex de fichier .htaccess
Celle-ci sert à interdire ces 22 fichiers index :
p.html, .shtml, .xhtml, ps.html, px.html, psx.html, .txt, .asp, .aspx, .cfm, .cfml, .cgi .pl, .php3, .php4, .php5, .php6, .php7, .php8, .php9, .jsp, .xml
Ce regex sert souvent pour que seul "index.php" ne soit pas rejeté (normalement le seul du site en question).<FilesMatch "^(index)\.(p?s?x?htm?|txt|aspx?|cfml?|cgi|pl|php[3-9]|jsp|xml)$">
Require all denied
</FilesMatch>
VIII - Aller plus loin
- Un testeur de Regex en ligne : https://www.regex101.com
- Un tutoriel complet (Regex et .NET) :https://stormimon.developpez.com/dotnet/expressions-regulieres
- La documentation de Python sur les Regex
- Le très bon manuel (en anglais) de GNU.org : Regular-Expressions
- l'historique des regex sur Wikipedia
Vous avez aimé cet article, partagez-le !

Le premier qui dit que j'ai mauvais caractère, c'est ma main dans la figure.